
The Data Communication Problem
Complex software platforms involve many systems - frontend applications, backend services, databases, message/event queues, and other external services. Data flows across the many paths between these systems, and the structure of that data changes over time to meet ever-changing requirements. This creates a lot of challenges - how do we ensure services agree on the structure of this data? How do we detect and handle scenarios where the data is malformed? How can we safely change the definition of this data?
Whilst there are existing solutions to solve some of these problems for specific use cases, like gRPC for service-to-service communication, or OpenAPI for REST schema definitions, or the many IDLs (Interface Definition Languages), at Instant we decided to go with a custom-built solution that would give us the flexibility to cover all of our use cases in a single standardised way, whilst keeping ourselves open to future migrations to these existing solutions should our priorities change.
These challenges are not unique, and our approach to address them is likely not entirely unique either. Depending on your team’s needs, you may choose to build your own schema management tools, or you might choose to adopt a more out-of-the-box solution. Regardless, we hope that sharing our learnings in this post can shed some light on the practices that can help ensure robust data communication.
Shared Type Definitions
The first goal of our schema management system is to provide common type definitions between systems.
At Instant, most of our stack is written in TypeScript, so we’d like to take advantage of the compile-time type safety and type expressiveness offered by the language.
Let’s explore a simple example - a frontend web application communicating to a backend via a REST API. The backend API has a createUser endpoint that accepts a request body:
This structure can be represented with a fairly simple type definition:
Suppose the frontend and backend both have access to this common definition, we should have confidence that both systems are adhering to the same data structure. However, that’s still not guaranteed - what if the caller accidentally references the wrong type? Or bypasses type safety (e.g. using TypeScript’s any type)? What if a new field is added to the type, but one side continues to use the old definition?
The next goal of our system is to defensively protect against these scenarios, by providing the ability to validate the data at run-time.
Run-time Validation
All of the type safety offered by TypeScript only exists at compile-time. Once the code is compiled (or rather, transpiled into JavaScript) all type information is completely lost.
For run-time validation, we need a schema to validate our data against. We went with Joi, which describes itself as a “powerful schema description language and data validator for JavaScript [and TypeScript]”. Following on from our createUser example, here is what the schema definition for our User object could look like:
We can then take that schema to validate that a given object conforms to this schema.
So we previously had a way of enforcing compile-time validation through TypeScript type definitions, and now we also have a way of executing run-time validation through object schema definitions. But how do we ensure the type definitions and schema definitions correspond with one another?
Generating Types From Schemas
Ideally we should have a single source of truth for the definition of a data type, any other definitions can be generated from that source of truth. Naturally we went with the schema objects as the source of truth, since the metadata described by these schema objects is easily inspectable at runtime. What we came up with is a TypeScript interface generator, that reads schema definitions and (you guessed it) generates corresponding TypeScript interfaces.
Since we’re not trying to re-invent every wheel, we looked for existing tools that we could leverage to help with code generation. Fortunately we found a joi-to-typescript npm package to help with that.
What we ended up with is a repository where we can define schemas, and have TypeScript interfaces generated from those schemas. All of the data definitions (source and auto-generated) are then exported as a private npm package.
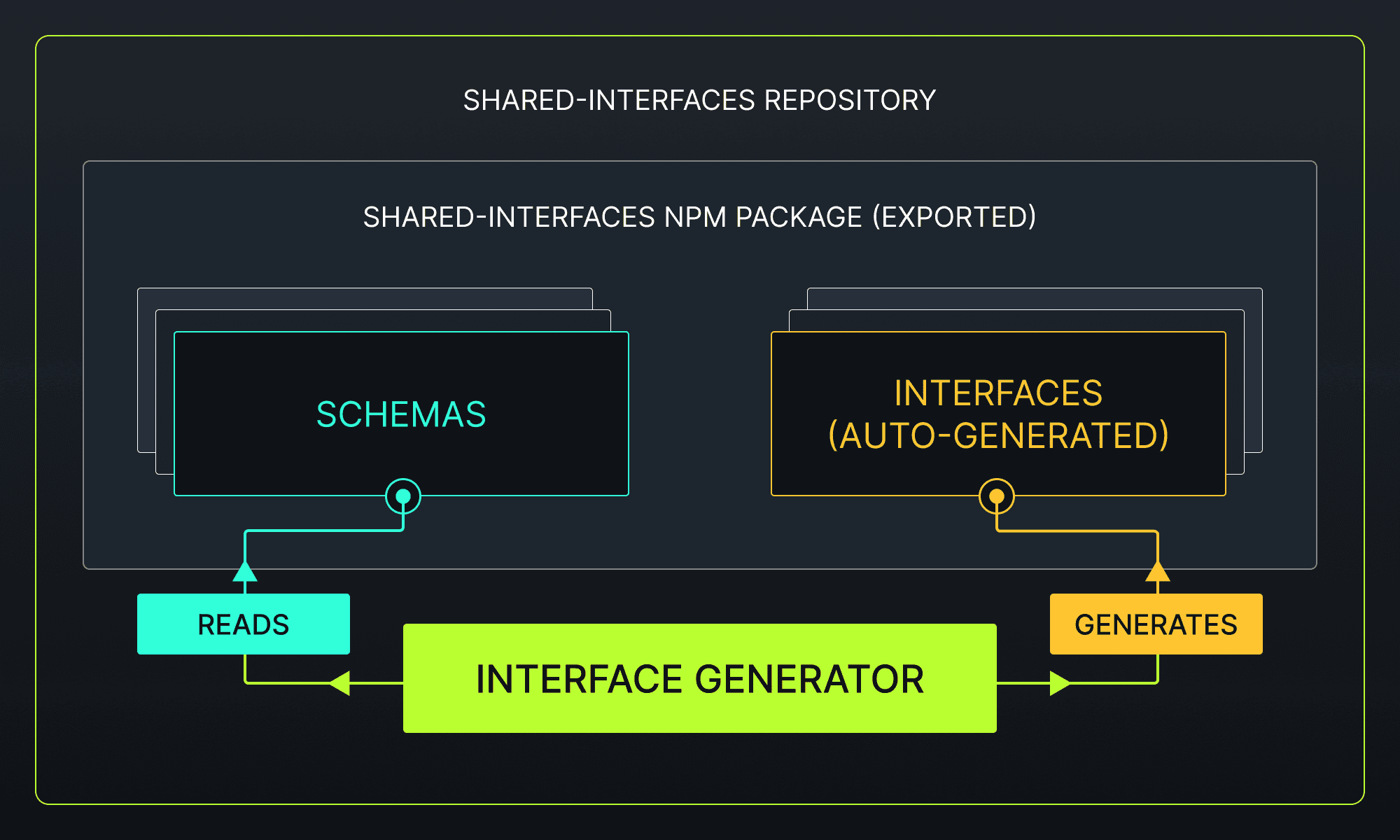
Continuing on with our example - the frontend and backend services can each import this package to access statically-typed definitions of our shared data structures. Additionally, the backend can validate any incoming (or outgoing) data to ensure the contracts between services are upheld, and to give confidence in casting untyped data to a specific type. Run-time validation provides a defensive approach to request handling, without it a request could process partially before malformed data causes an error, at which point unwanted side effects may have already taken place.
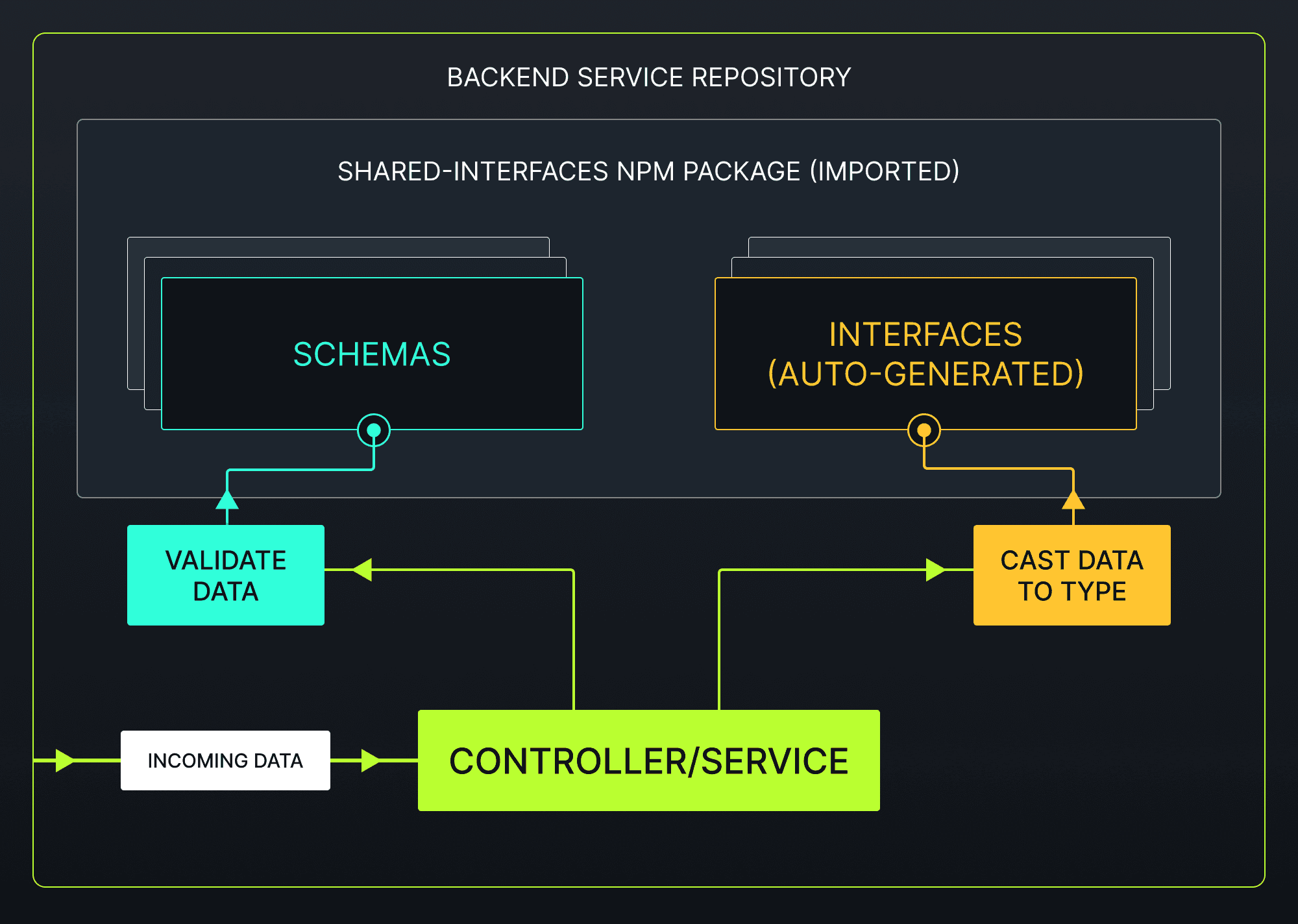
Now we have compile-time type safety, run-time validation, and a mechanism to keep these definitions in sync across both formats. And in case you’re concerned about the performance cost from introducing validation to every endpoint invocation - our testing shows that the time to run an object validation is on the order of microseconds (even with much more complex schemas than this example).
Comprehensive Schemas
The schemas we’ve looked at so far have been fairly simple. Both Joi and TypeScript support much more comprehensive definitions that we can make use of. Let’s take another look at the example user schema and objects from earlier (now also including the generated TypeScript definition):
In this example the user2 object does not conform to the defined schema. But let’s suppose that this object does in fact represent a valid variation in the user object that we’d like to support - that is, a user could either have type equal to B2B, in which case they also require a companyId to be specified, or they could have type equal to RETAIL in which case a companyId should not be specified. The schema and the corresponding TypeScript type could be expressed as such:
This example utilises Literal Types and Union Types (expressed in the schema definitions using Joi’s valid and alternatives constraints respectively), which are just a couple of the many expressive language features that can be leveraged for robust type definitions.
Schema Changes
Managing schema changes is almost always a tricky problem. One of the advantages of schema-first design is that your schema changes are decoupled from the rest of your implementation, and whilst making a schema change might feel like an additional step - this decoupling helps ensure that schema changes are made with intent and can be reviewed in isolation, hopefully making it easier to detect any “breaking” changes.
We consider a change to be “non-breaking” if data that conforms to the old version of the schema is still compatible to the new version. For example, introducing a new optional field is non-breaking - since the field is optional, data that was targeted to the old schema will still be valid according to the new schema. Adding a required field, or removing a field, would be considered a “breaking” change because the new schema definition will suddenly start rejecting data that was targeted to the previous schema definition.
For external-facing APIs, a breaking schema change means releasing an entirely new version of the API, whilst continuing support for the old API for some time. This is why careful upfront schema design is incredibly important.
For internal-only data communication, a breaking change can still be achieved with a lot of careful coordination. For example, to add a new required field, first make the schema change in a non-breaking way (i.e. add it as an optional field). Next, ensure all consumers of this schema have upgraded to the latest version and are providing the new field all of the time. As an optional step for even greater confidence, you can add error logging to detect any instances where the new field is not provided and let that run for some time to ensure the new field is always specified. Once you have confidence that all consumers of the schema are updated, you can make the “breaking” schema change (i.e. mark the field as mandatory).
Conclusion
We’ve taken a look at how we’ve used code-generation to implement a custom schema-first approach to managing service-to-service data communication.
Our schema definitions are the source of truth for our data types. These definitions serve a very similar purpose as an IDL (Interface Definition Language), in fact we often refer to them internally as our IDL. These schema definitions enable:
Run-time validation of data
The generation of TypeScript type definitions, and by extension, compile-time safety of our data types (as well as all the other benefits of having these TypeScript definitions, such as auto-complete in our IDE).
And due to the expressive power of TypeScript, we are able to model and validate comprehensive data structures.
This has been a fairly high-level overview, and these types of systems can certainly be extended further - perhaps you could also generate documentation based on your schema, or add support for other languages.
We hope you found this one informative, stay tuned for more tech posts in the future!